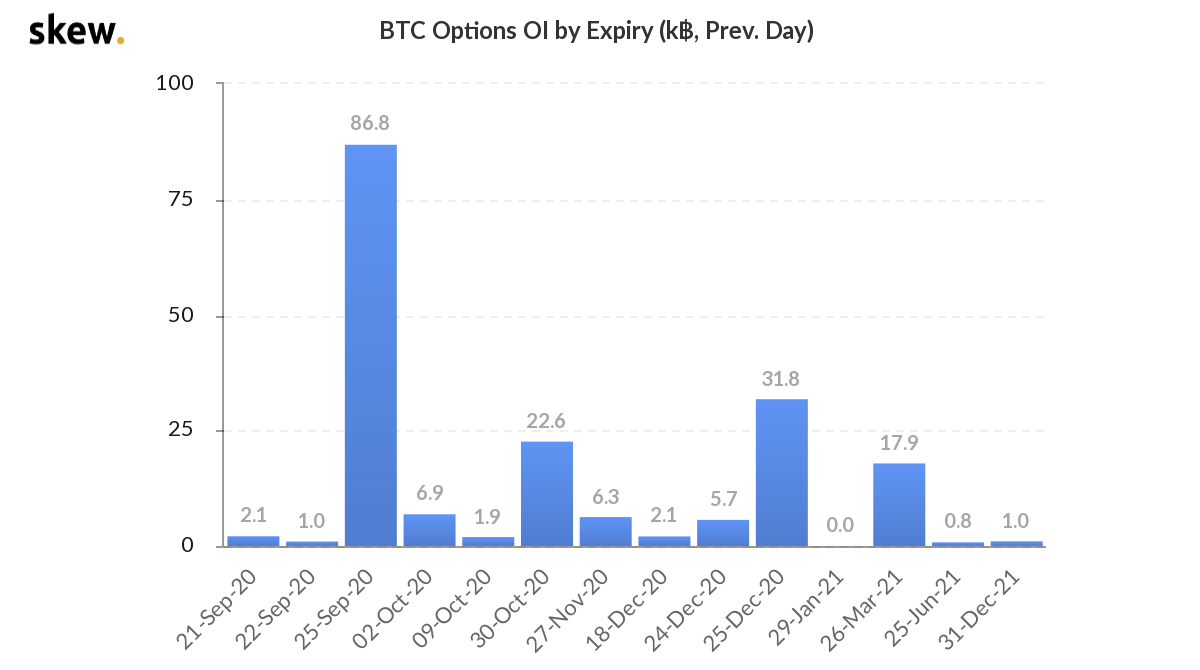
Cryptocurrency’s option market continue to grow this year. The open interest of the coming monthly expiry BTC option is around $1 billion.
In the traditional financial world, it’s very difficult (costy) for individual to acess the market data, let alone analyze and trade option systematically. But the crypto market is open for everyboday, we can easily subcribe to realtime market data and trade programatically with open API provided by all crypto exchanges. So in my next series post, I’ll try to build a platform for crypto option analysis and trading.
Choose Database
As a first step, I’ll try to use Python to subscribe realtime market data and persist into local disk (to the cloud in the later post), so it can be used for analytic research. To store the data, we need to find out a proper database, which should have below characteristics:
- Efficiency - enpower fast query in large scale
- Scalbility - easy to scale up, efficient compression support to save disk usage
- Interoperability - support access by different language or different platform
By its nature time series data is columnar, KDB+ is one of the best solution to work with. It is a fast database which also enables you to query and manipunate data in memory using its own language Q. However KDB+ is not open source, it can only be used for non-comercial purpose for free. Thanks to Saeed who has compared several state of the art time series database in his post. Based on that, we decide to combine Apache Parquet as the storage format, Apache Arrow as the memory format and PyArrow as the processing engine.
Subscribe Market Data
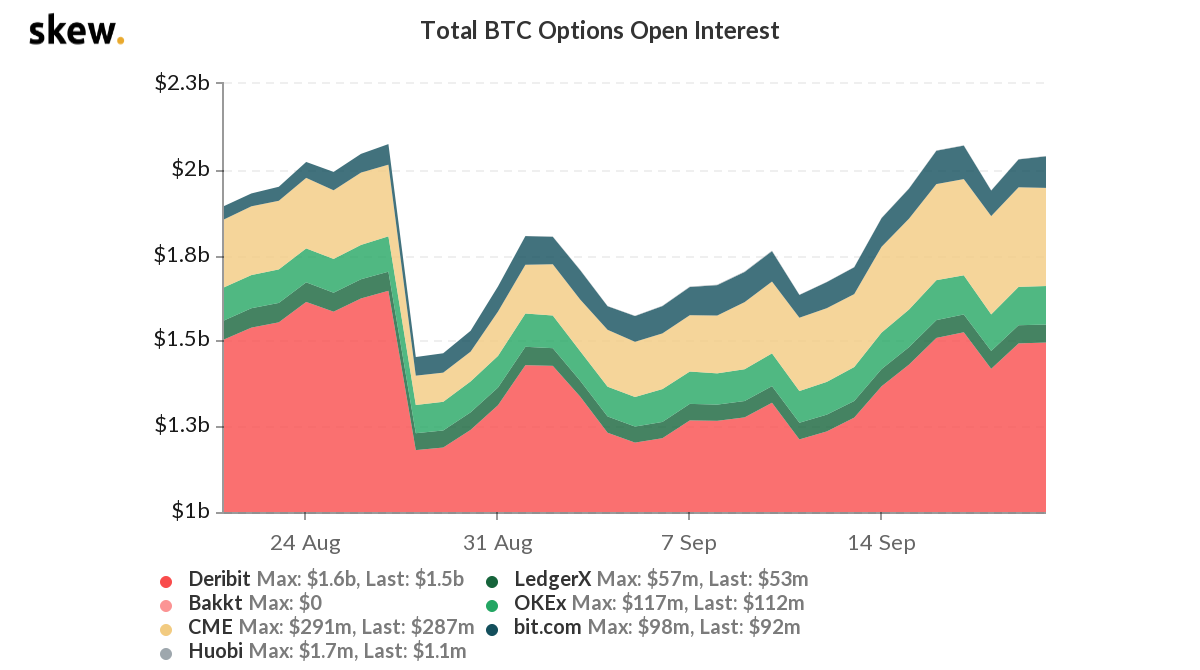
From the Skew statistic, Deribit is the most active exchange for BTC option, so I’ll start there.
 By checking the Deribit API document, we found that the market data is public, we don’t even need to create a account. In this post, we’ll need below APIs:
By checking the Deribit API document, we found that the market data is public, we don’t even need to create a account. In this post, we’ll need below APIs:
public/get_instruments
public/subscribe
public/set_heartbeat
public/test
get_intruments API is used to retrieve the list of open contract, which will then be used to build the subcription channels. The subscribe API is used to subscribe market data. During the test, the server will terminate the web socket connection after 10 minutes if no heartbeat was set. To keep the connection alive, we need to set_heartbeat with an interval, and respond to the heartbeat request with test API.
Persist Market Data
Since we are listening to the ticking data, we should incrementally write data into the Parquet file. The only way to do so is via the ParquetWriter class.
import pyarrow.parquet as pq
# ... define the table schema and create an parquet file writer
self.ticker_schema = pa.schema([
('timestamp', pa.timestamp('ms')),
('symbol', pa.string()),
('index_price', t_float),
('mark_price', t_float),
('last_price', t_float),
('mark_iv', t_float),
('biv', t_float),
('aiv', t_float),
('bbp', t_float),
('bbs', t_float),
('bap', t_float),
('bas', t_float),
('delta', t_float),
('gamma', t_float),
('vega', t_float),
('theta', t_float),
('rho', t_float)
])
self.ticker_writer = pq.ParquetWriter("ticker.parquet",self.ticker_schema)
# ... build PyArrow table from a list of array, and write to the parquet file
tickers = pa.table(
[
self.ticker_ts, # timestamp array
self.ticker_sym, # symbol array
self.ticker_index_price,
self.ticker_mark_price,
self.ticker_last_price,
self.ticker_mark_iv,
self.ticker_biv,
self.ticker_aiv,
self.ticker_bbp,
self.ticker_bbs,
self.ticker_bap,
self.ticker_bas,
self.ticker_delta,
self.ticker_gamma,
self.ticker_vega,
self.ticker_theta,
self.ticker_rho
], self.ticker_schema)
self.ticker_writer.write_table(tickers)
# ... close the writer to ensure the metadata of footer are appended to the parquet file
self.ticker_writer.close()
Play with Market Data
I ran the script on my Mac for the whole night, and got around 4M rows, the size of the parquet file is around 665M.
import pyarrow.parquet as pq
import pandas as pa
ticker = pq.read_parquet('ticker.parquet')
df = ticker.to_pandas()
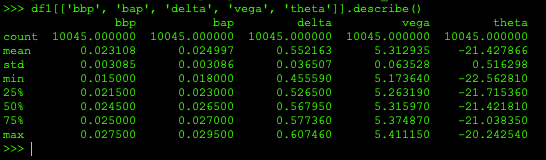
df1 = df[df['symbol']=='BTC-25SEP20-11000-C']
df1[['bbp', 'bap', 'delta', 'vega', 'theta']].describe()
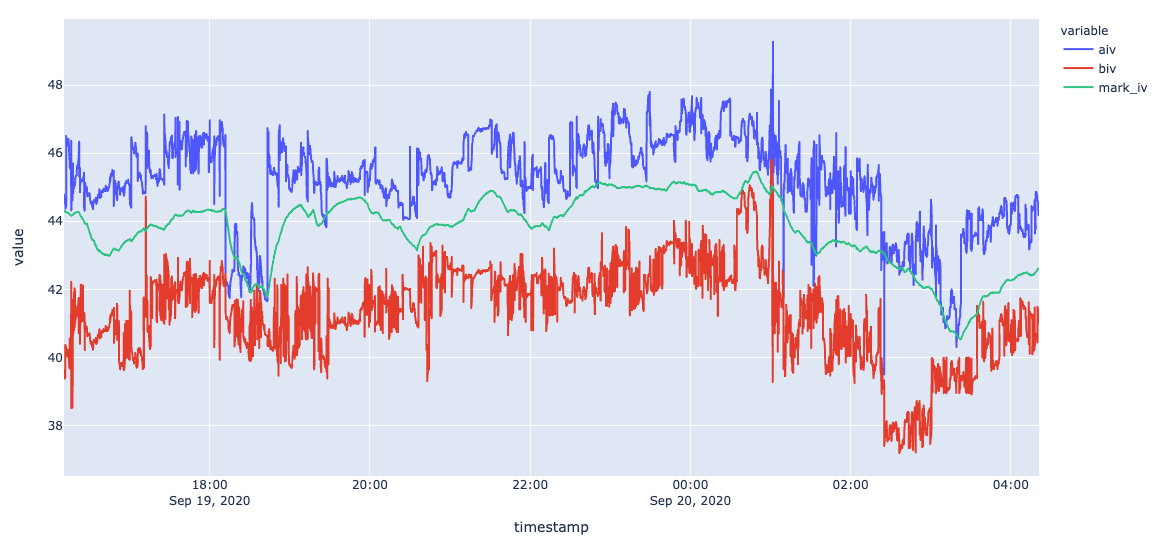
import plotly.express as px
px.line(df1, x='timestamp', y=['aiv', 'biv', 'mark_iv']).show()