本文主要分析Lucene源码中关于文本处理的部分,该功能封装在analysis包中。本文并不涉及Lucene的使用方法介绍。
![]() Lucene的文本处理包括:去除非字母字符、大写字母转换成小写、去除停用词、词形还原…等等,并且可以通过自定义扩展实现所需的处理。Analyzer抽象类是Lucene进行文本处理的重要类,所有继承Analyzer的子类都需要重写tokenStream()方法,该方法将文本信息转换成Token流并返回一个TokenStream对象,每一个Token除了包含文本单词以外,还包括一些重要的元数据,如:该单词的位置信息,偏移量等。TokenStream可以逐一枚举所有的Token并实现对Token的处理和转换。在Lucene中有两类重要的TokenStream,分别是Tokenizer和TokenFilter,下图描述了它们之间的类图关系:
Lucene的文本处理包括:去除非字母字符、大写字母转换成小写、去除停用词、词形还原…等等,并且可以通过自定义扩展实现所需的处理。Analyzer抽象类是Lucene进行文本处理的重要类,所有继承Analyzer的子类都需要重写tokenStream()方法,该方法将文本信息转换成Token流并返回一个TokenStream对象,每一个Token除了包含文本单词以外,还包括一些重要的元数据,如:该单词的位置信息,偏移量等。TokenStream可以逐一枚举所有的Token并实现对Token的处理和转换。在Lucene中有两类重要的TokenStream,分别是Tokenizer和TokenFilter,下图描述了它们之间的类图关系:
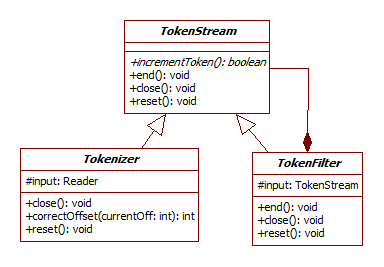 从上图中,可以看出TokenFilter和TokenStream之间有组合关系,也就是说,TokenFilter中可以再封装一个TokenStream对象(可以是Tokenizer也可以是TokenFilter)。Tokenizer从java.io.Reader读取字符并创建Token流,而TokenFilter读取Token流,并输出新的Token流(通过添加、删除Token,或者修改Token属性)。Lucene中文本分析链一般从一个Tokenizer开始,然后经过若干个不同TokenFilter,最后输出Token流:
从上图中,可以看出TokenFilter和TokenStream之间有组合关系,也就是说,TokenFilter中可以再封装一个TokenStream对象(可以是Tokenizer也可以是TokenFilter)。Tokenizer从java.io.Reader读取字符并创建Token流,而TokenFilter读取Token流,并输出新的Token流(通过添加、删除Token,或者修改Token属性)。Lucene中文本分析链一般从一个Tokenizer开始,然后经过若干个不同TokenFilter,最后输出Token流:
 Lucene中文本分析链的创建时同过TokenStream的嵌套形成的,例如:在创建第一个TokenFilter对象时,需要传递Tokenizer对象给它;在创建第二个TokenFilter对象时,需要传递第一个TokenFilter对象给它;依次类推,从而形成一个分析链。文本按照TokenStream的嵌套顺序,依次被处理。
Lucene中文本分析链的创建时同过TokenStream的嵌套形成的,例如:在创建第一个TokenFilter对象时,需要传递Tokenizer对象给它;在创建第二个TokenFilter对象时,需要传递第一个TokenFilter对象给它;依次类推,从而形成一个分析链。文本按照TokenStream的嵌套顺序,依次被处理。
下面我将通过一段具体的代码分析TokenFilter中,数据流是如何传递的:
1
2
3
public TokenStream tokenStream(String fieldName, Reader reader) {
return new StopFilter(enablePositionIncrements, new LowerCaseTokenizer(reader), stopWords);
}
以上代码中出现在StopAnalyzer类中,StopAnalyzer为Analyzer的子类,StopFilter为TokenFilter的子类,LowerCaseTokenizer为Tokenizer的子类。tokenStream方法从Reader读取文本,创建LowerCaseTokenizer对象,并将其作为参数传递给StopFilter对象。文本在LowerCaseTokenizer中被转换成Token流,然后经过StopFilter去除Token流中的停用词。下面的increamentToken()是StopFilter中逐一处理Token的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public final boolean incrementToken() throws IOException {
// return the first non-stop word found
int skippedPositions = 0;
while (input.incrementToken()) {
if (!stopWords.contains(termAtt.termBuffer(), 0, termAtt.termLength())) {
if (enablePositionIncrements) {
posIncrAtt.setPositionIncrement(posIncrAtt.getPositionIncrement() + skippedPositions);
}
return true;
}
skippedPositions += posIncrAtt.getPositionIncrement();
}
// reached EOS -- return false
return false;
}
以上代码表明,StopFilter每次从LowerCaseTokenizer中取出一个Token,判断该Token是否在stopWords中,若存在则跳过该Token(即过滤掉),若不存在则修改该Token的位置属性;处理完之后再取下一个Token。由此可知,Token流在经过多个TokenFilter时,是一个Token先经过所有的TokenFilter,然后再去下一个Token经过所有的TokenFilter;而并不是所有的Token先经过第一个TokenFilter,然后所有的Token再经过下一个TokenFilter。